【業界キーパーソン・インタビュー(2)】
自動車ソフトの品質保証問題。プロダクトラインが浸透、次はAI変革
—— 早稲田大学 教授 鷲崎 弘宜 氏
自動車のソフトウェア品質を確保・維持するため、開発企業はさまざまな手法の導入を試みてきました。2000年代以降は、多数のソフトウェア部品を組み合わせて、多品種の製品を効率良く作り出すプロダクトライン開発の導入が進みました。最近では、ソフトウェアテストにAI技術を取り込む動きが目立っています。ここでは、早稲田大学 教授の鷲崎 弘宜 氏に、自動車分野のソフトウェア品質の課題、およびソフトウェアテストの研究動向などについて話をうかがいました。聞き手は、弊社CEO 代表の岩井 陽二です。

早稲田大学 理工学術院 基幹理工学部 教授の鷲崎 弘宜 氏
プロフィール:早稲田大学 グローバルソフトウェアエンジニアリング研究所⻑・教授。国立情報学研究所 客員教授。株式会社エクスモーション 社外取締役。人間環境大学 顧問。株式会社SI&C 顧問。IEEE Computer Society 2025年会⻑。情報処理学会 ソフトウェア工学研究会 主査。日科技連 ソフトウェア品質管理研究会 運営小委員会 委員⻑。JST CREST 信頼されるAI システム領域アドバイザ。ISO/IEC/JTC1 SC7/WG20 Convenor。IoT・AI・DXリカレント教育プログラム「スマート エスイー」事業責任者。
プロダクトライン開発には追跡性管理が必須
——自動車ソフトウェアの品質保証は、なぜ難しいのでしょう?
鷲崎:一つの要因は、異なる性質をもったさまざまなサブシステムが統合されて出来上がったシステムである、という点です。セーフティクリティカルなところとそうでないところ、リアルタイム制約のあるところとないところ、ルールベースで決定的にふるまうところとデータや機械学習に基づいて非決定的にふるまうところ、などが混在しています。
——自動車は、機能の面でも複雑です。
鷲崎:ハードウェアに近い制御まわりから、インフォテインメントシステムに代表される情報系まで、異なる種別のシステム機能が組み合わさって構成されています。さらに、ソフトウェア部品としても最終製品としても非常に多品種で、その結果として、膨大な構成の組み合わせが存在します。このことも、品質保証やテストの難しさにつながっています。
——歴史的に見ると、ソフトウェア品質問題が自動車業界で騒がれるようになったのは、いつごろからですか?
鷲崎:かなり以前から問題として捉えられていますが、特にソフトウェアが急速に複雑かつ大規模化した90年代後半に多くの議論がおきています。またそのころから、オールインワンで品質問題に対処できる統合的な仕組みが必要になる、と言われていました。そのような流れの一つとして、AUTOSAR(Automotive Open System Architecture)に代表される車載ソフトウェアアーキテクチャの標準化が進展しました。オールインワンはちょっと言い過ぎですが、標準に合わせていくことで、ソフトウェア部品の間のばらつきや差異がならされ、システム統合の難しさが緩和されました。これは、システムエンジニアリングの観点からは非常に理にかなった、王道の対応と言えます。
——標準化が進んだことで、開発手法に変化はありましたか?
鷲崎:2000年代以降、ソフトウェア部品や製品の種別のやりくり(開発計画や管理)はプロダクトライン開発と呼ばれる手法に基づいて行う、という動きが活発になりました。プロダクトライン開発とは、多くのソフトウェア部品を用意し、それらを体系的に組み合わせて、さまざまな製品のバリエーションを効率良く生み出していこう、という考え方です。こうした取り組みは、今なお続いています。
——プロダクトライン開発を実践する場合、どのような考え方が必要になりますか?
鷲崎:トレーサビリティ(追跡性)を考える必要があります。プロダクトライン開発では、さまざまなソフトウェア部品を組み合わせてシステムを構成します。どの要求(機能要件、非機能要件を含めて)に対してどのソフトウェア部品が対応しているのか、あるいは対応していないのか、をきちんと管理し、いつでも追跡できるようにしておかなければなりません。
——追跡に必要な情報が失われていた場合、どう対処すればよいのでしょう?
鷲崎:私たちの研究室では、共同研究の成果として、自然言語処理や機械学習によってプログラムコードを解析し、要求や設計などの文書の部分部分とコードの対応関係を明確にする技術を開発しています(図1)。この手法を使えば、失われていたトレーサビリティを後から復活させることが可能です。
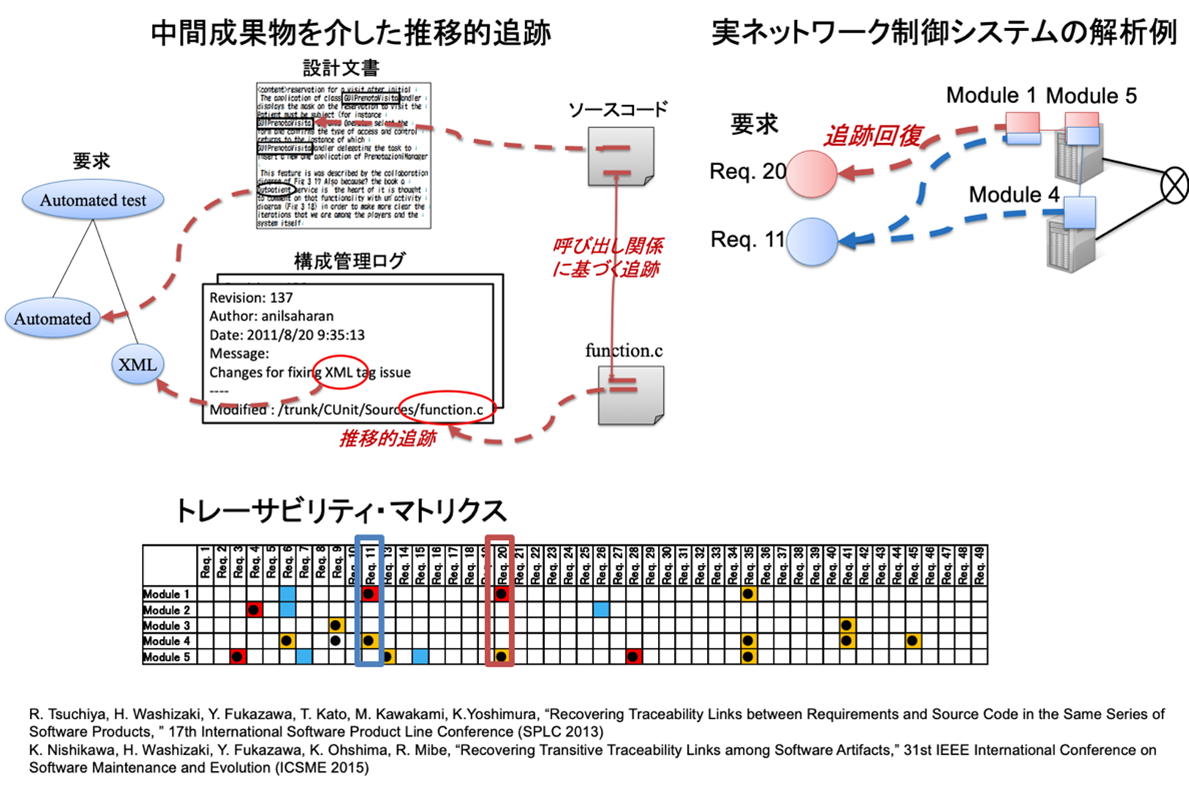
図1 自然言語処理や機械学習による追跡
※ 本図は鷲崎様に提供していただきました。
——自動車ソフトウェアの規模は増加の一途をたどっています。規模の大きいソフトウェアの品質を考える場合、どのような点に注意が必要ですか?
鷲崎:ソフトウェア品質を階層的な視点で捉えることが重要です。プログラムコードの部分部分の品質だけを見るのではなく、それをまとめたモジュールや部品のレベル、さらにはそれらを集約したアーキテクチャのレベルの品質も見ていく必要があります。
——その場合、ソフトウェア品質の計測はどのように行うのでしょう?
鷲崎:まず、静的コード解析などを利用して、コードの部分部分の品質をさまざまな観点(メトリクス)に基づいて測定・評価します(図2)。次に、解析結果のデータを組み合わせて基礎を得つつ、その上位のモジュールや部品、さらに上位のアーキテクチャの一部、そしてアーキテクチャ全体というように、さまざまなレベルで品質につながる特徴を解析評価します。私たちの研究室では、このような階層的なソフトウェア品質をシームレスに可視化する技術を開発しています。この研究成果は実際に連携先を通じて製品サービス化されており、自動車メーカなどに向けたコンサルティング業務に利用された実績があります。
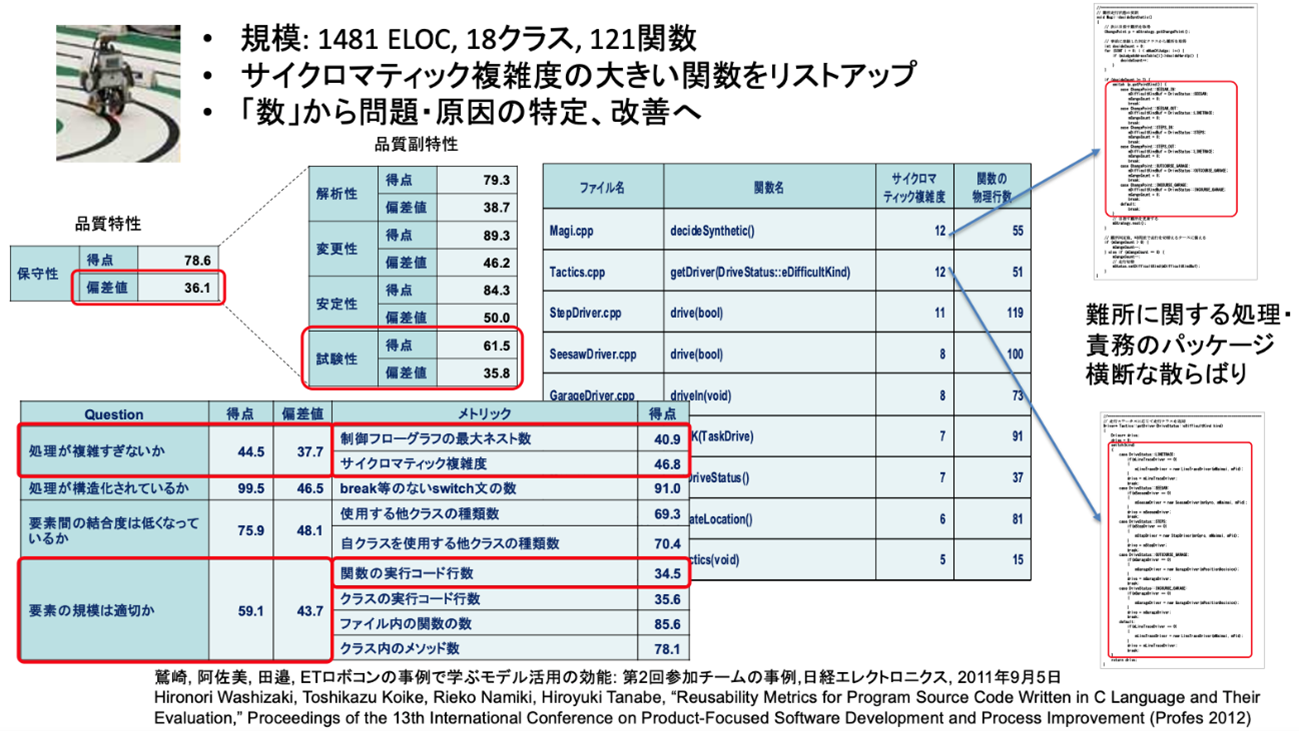
図2 品質測定評価の例(ETロボコンにおけるコード改善例)
※ 本図は鷲崎様に提供していただきました。
——階層的なソフトウェア品質を可視化すると、どのような利点があるのでしょう?
鷲崎:階層構造の中のどの部分に問題が多いのか、あるいは少ないのか、といった統計的な分布を把握できます。このような解析を行った上で、問題が多い箇所について、例えばアーキテクチャのレベルで処理の依存関係が巡回していないか、複数のパッケージの間でデータの出入りが発生している時、それらの依存関係が複雑になりすぎていないか、などを重点的にチェックし、着実に修正や改善を施していきます。
単純な欠陥の修正はAIにまかせる
——AI技術に注目が集まっています。ソフトウェア品質確保の観点で、AIはどのように使われていくのでしょう?
鷲崎:私がAIの適用を有効だと考えている局面は、四つあります。すなわち、1) テスト文書の分析・評価、2) 欠陥(バグ)位置の特定、3) 欠陥の自動修正、4) テストの優先順位付け、です。
——「1) テスト文書の分析・評価」とは、具体的にどのような作業を指しているのでしょう?
鷲崎:テスト工程では、バグレポートや故障管理票表といった文書を使いながら、欠陥を修正していきます。例えばバグレポートの中には、欠陥について重複する記述や類似の記述が多く存在します。欠陥が「同じものだった」というのは非常に重要な情報です。それだけ頻出しているわけですから、しっかりと取り扱うことが大切ですし、同じ対処の仕方を他のところにも適用できる可能性があります。私たちの研究室では、このようなテスト文書の分析・評価にAI、特に機械学習を利用する方法について研究しています。
——機械学習によって得られるのは、欠陥の類似性の情報だけですか?
鷲崎:最近ではさらに一歩進めて、「なぜ、このような欠陥に至ったのか」、「具体的にどう処理すればよいのか」、「どのような欠陥は早く修正できて、どのような欠陥は処理に時間を要するのか」といったことを推定する研究も行っています(図3)。統計や機械学習によって因果関係を分析したり、過去のデータの傾向から因果関係を見いだしたりすることで、成果を上げています。
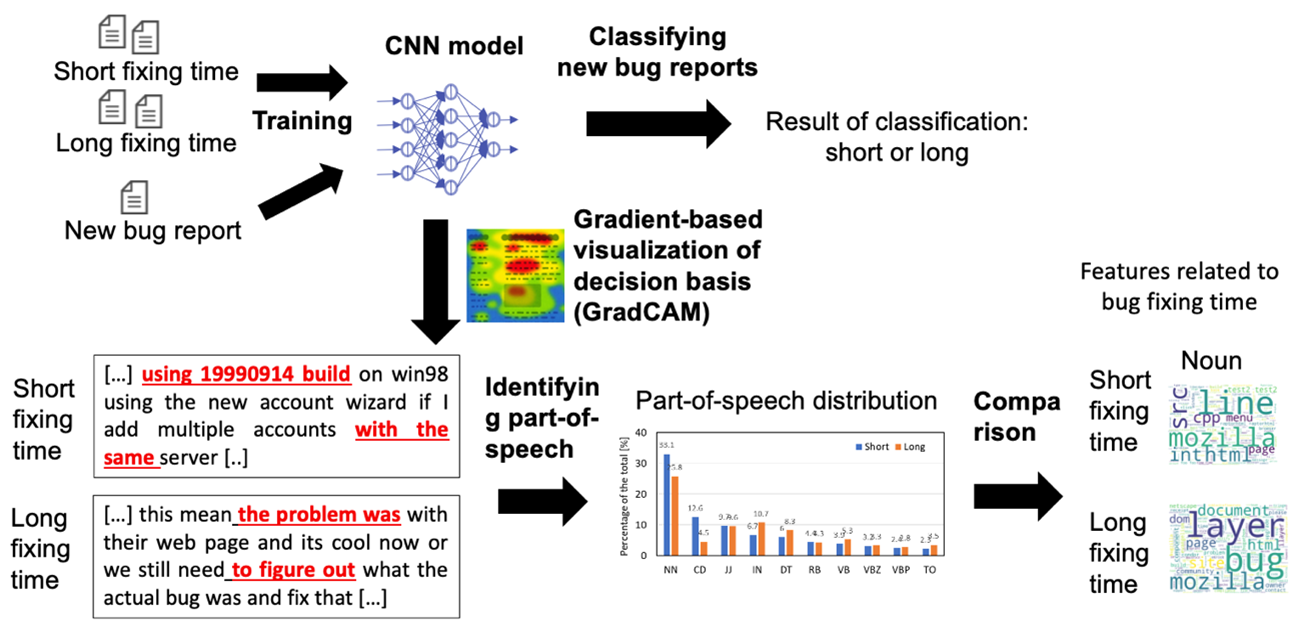
図3 深層学習に基づく欠陥修正時間の予測と可視化
※ 本図は鷲崎様に提供していただきました。
——「2) 欠陥位置の特定」では、AIをどのように使うのでしょう?
鷲崎:テストしていくと、どこかに誤りがあることが分かります。しかし、具体的にどこに誤りがあるのかを特定しようとすると、多くの時間がかかります。そこで、成功したテストケースと失敗したテストケースをたくさん集めます。成功したテストの実行パスと失敗したテストの実行パスの差分をAIで分析し、プログラムの中のどのあたりに欠陥が潜んでいそうなのかを推定します。
——「3) 欠陥の自動修正」では、どのような技術が使われていますか?
鷲崎:私たちの研究室は、以前に、遺伝的アルゴリズムを用いた手法を提案しました。これは、生物の遺伝子組み換えを模倣して、いろいろなパターンを生み出していく方法です。テストが通らない箇所(欠陥位置)が見つかったとき、そこに対して、こんな組み換えをしたらどうなるのか、別の組み換えをしたらどうなるのか、といったことを大量に試します。そうすると、いつかどこかでテストが通る組み換えの仕方(欠陥の修正方法)を見つけられる可能性があるわけです。さらに現在では、欠陥の自動修正に生成AIを使う手法の研究が盛んとなっています。さらに、こうした欠陥位置の推定や修正における基本的な考え方は、プログラムに加えて機械学習や深層学習モデルの自動調整についても有用です。そこで私たちの研究室では、自動運転を支える深層学習モデルを題材として、性能目標に応じて自動調整の手法を効果的に適用し評価し続ける枠組みを構築しています。
——「4) テストの優先順位付け」とは、どのような取り組みですか?
鷲崎:テストケースの中には、あまり重要ではないテストと重要性の高いテストが混在しています。私たちは、どのテストを優先的に行うべきか、どのテストは実施する優先順位が低いのか、といったことをAIで判定する手法も研究しています。過去の類似した開発プロジェクトのテスト結果をベースに、新たな開発プロジェクトにおけるテストの優先度を推定しています。
——AIが欠陥位置の特定や自動修正を行うようになれば、デバッグ作業は不要になるのでしょうか?
鷲崎:人間が見逃すような複雑な欠陥を自動修正するのは、まだ難しい状況です。例えば、複数のモジュールやソフトウェア部品がかかわっている欠陥、あるいはタイミングに起因する欠陥を修正できるようになるには、もう少し時間がかかりそうです。だれが見ても明らかにおかしいと分かるような単純な欠陥の修正はAIにまかせ、そうでないものの修正は人間が行う、といった役割分担になっていくと思います。
持続可能なソフト開発に注目
——T LEAD SCIENCESは、事業目的の一つとして「科学技術によるビジネスの革新・打開をめざす顧客への計画および推進の支援」を掲げています。
鷲崎:私は2025年1月に、世界最大のコンピュータ学会IEEE Computer Societyの会長に就任しました。この学会には、毎年、コンピューティング技術にかかわるメガトレンドを予測し、世の中の研究や実践に対して道筋を示していく、という役割があります。このメガトレンドに則した形で、T LEAD SCIENCESとの協業の形を描いていけるのではないか、と考えています。
——メガトレンドとは、どのような内容ですか?
鷲崎:大きく三つのテーマがあります。一つ目は、AI技術の進展です。生成AIの普及もそうですし、次世代のAIアルゴリズムや低消費電力のAI、汎用人工知能(AGI:Artificial General Intelligence)などの研究開発も進みます。二つ目は、AIが駆動する形で、さまざまな領域のデジタルトランスフォーメーション(DX)が加速することです。三つ目は、コンピューティング技術が最終的に社会のサステナビリティ(持続可能性)の実現に貢献していく、ということです。
——ソフトウェアは、サステナビリティとどう関係するのでしょう?
鷲崎:ソフトウェア工学の領域の一つに、サステナブルソフトウェア工学があります。それをもっと加速させていく必要がある、ということを、私はさまざまな場面でお伝えしています。サステナブルなソフトウェアの開発においては、ビジネス的な価値だけでなく、社会にどう貢献していくのか、という視点も重要になります。
——サステナブルなソフトウェア開発と言うと、環境負荷を抑えられる、電力消費の少ないソフトウェアを作る、ということですか?
鷲崎:それも、一つの「サステナブル」ですが、それだけではありません。ソフトウェアの開発時や配布時、そして使用を停止して廃棄する時の問題も考えます。例えばソフトウェアの廃棄時に、それまで使っていたデータが残ったとします。それをどう取り扱っていくのか。他のサービスや製品で続けて使えるのか。互換性は? 残ったデータの保管方法は? そういったところも含めて考えないといけません。さらに、基準や指標、プロセス、ツールという側面も見ていく必要があります。このような課題の全体像は、GREENSOFT Modelに代表される参照モデルとして提示されています(図4)。
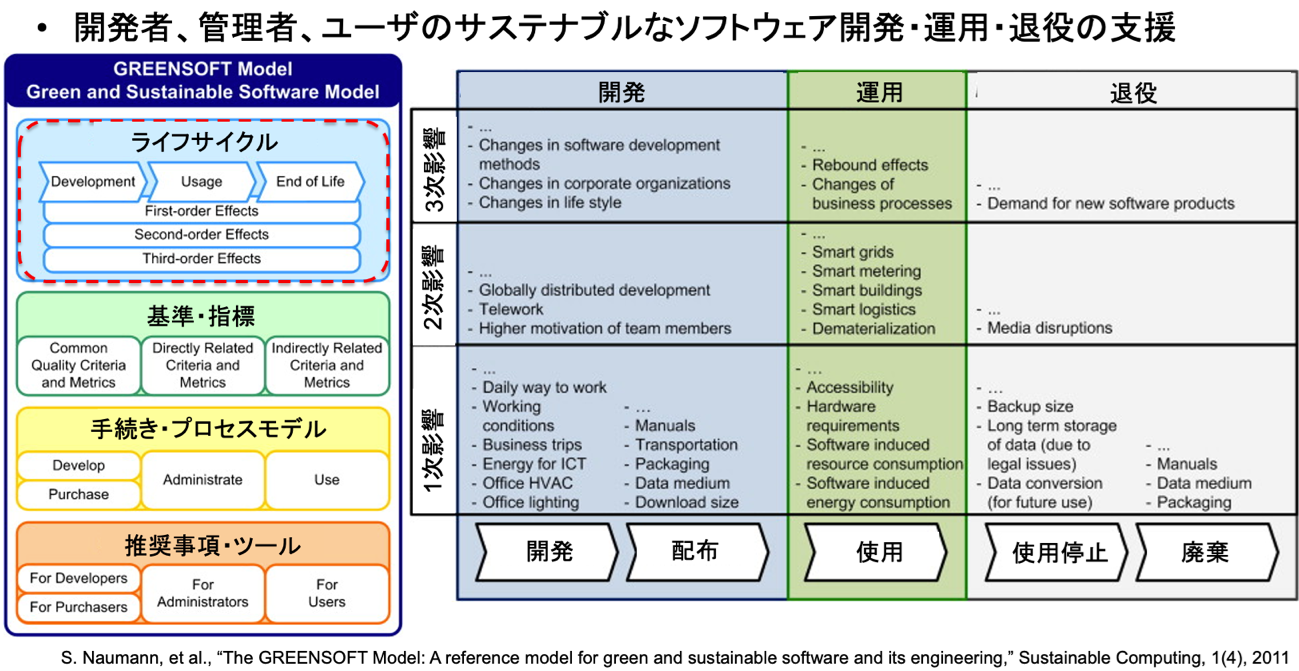
図4 GREENSOFT Model(サステナブルなソフトウェア開発・運用の参照モデル)
※ 本図は鷲崎様に提供していただきました。
——サステナブルソフトウェア工学は、日本ではあまり知られていないように見えます。
鷲崎:私は、早稲田大学が中心となって展開している、IoT・AI・DX推進人材の育成を目的とした「スマート エスイー(Smart SE)」というリカレント教育(社会人の学び直し)プログラムの事業責任者をしています。そこで、サステナブルな開発のあり方をエッセンスとして取り入れています。自身の研究も含めて、GREENSOFT Modelなどに照らし合わせながら、「どこは実現できていて、どこが足りないのか」を考えています。T LEAD SCIENCESには、率先してサステナビリティ関連の課題に取り組んでいただきたい、と期待していますし、私もそのような仕事でご一緒したい、と思うところです。
——弊社への期待のコメントに感謝します。私たちが取り組んでいきたい、と考えているチャレンジの一つに、若い世代の就業機会の確保・維持を支援したい、というものがあり、その一環として産学連携できることが多々あると思っています。本日は、インタビューにご協力いただき、誠にありがとうございました。